
更新日:2025/10/10
Pythonで始めるAI
AI(人工知能)という言葉は、最近あらゆる分野で聞かれるようになりました。ただ、実際に「AI を始めたい」と思っても、「どこから手を付ければいいのか」「Python を使うメリットって何?」という疑問を抱く方は多いはずです。本シリーズの第1回では、Python を軸として AI の世界を基礎から理解できるように、丁寧に整理してご案内します。まずは AI と Python の関係性、AI の需要背景、AI の基本概念を例を交えながら解説します。
人工知能(AI:Artificial Intelligence)とは、人間の知的な行動をコンピュータで模倣し、自動化するための技術分野です。つまり、AIは人間の「学習」「推論」「認識」「理解」「判断」などの知的機能を、プログラムやアルゴリズムを通じて再現することを目的としています。
AIは、単に人間の作業を効率化するツールではなく、人間の知能そのものをシミュレーションする技術体系といえます。AIの進化により、コンピュータは人間のように経験から学び、過去のデータをもとに将来を予測し、より的確な意思決定を行うことが可能になりました。
AIが関わる代表的な分野としては、機械学習(Machine Learning)、ディープラーニング(Deep Learning)、自然言語処理(Natural Language Processing)、コンピュータビジョン(Computer Vision)などが挙げられます。これらが相互に組み合わさることで、AIは画像認識、音声認識、自動翻訳、医療診断、さらには自動運転といった多様な応用分野で実用化されています。
AIの根本的な特徴は「データから学習する」ことにあります。従来のプログラムは、人間があらかじめルールや手順をすべて定義する必要がありました。しかしAIは、膨大なデータを取り込み、その中からパターンや関係性を自動的に見つけ出し、自ら最適な判断を導き出します。この能力こそが、AIを単なるプログラムから「学習するシステム」へと進化させた要因です。
機械学習は、AIの中核を成す技術のひとつであり、「コンピュータがデータから自動的に学習し、改善していく能力」を指します。人間が直接プログラムを指示するのではなく、システム自身が経験をもとに学び、予測や分類を行うようになります。
例えば、スパムメールの検出システムを考えてみましょう。従来型のシステムでは、「この単語が含まれていたらスパム」といった明確なルールを人間が設定していました。一方で機械学習では、大量のメールデータを学習させることで、AIが自動的に「どのような特徴を持つメールがスパムなのか」を判断できるようになります。
機械学習には大きく分けて3つの主要な学習手法があります。
このように機械学習は、AIの「学習能力」を支える基礎技術であり、今日のAI応用のほとんどに利用されています。
ディープラーニング(深層学習)は、機械学習の一分野であり、人間の脳神経構造を模倣した「ニューラルネットワーク」を用いてデータを学習する技術です。特に画像認識や音声認識、自然言語処理などの分野で、従来の手法を凌駕する性能を発揮しています。
従来の機械学習では、特徴量(特徴を数値化したもの)を人間が定義する必要がありましたが、ディープラーニングではこの特徴抽出を自動で行います。これにより、人間が介入しなくてもシステムがデータの本質を自ら理解できるようになりました。
ディープラーニングの代表的なモデルには以下のようなものがあります。
ディープラーニングの発展は、AIの「認識精度」と「表現力」を飛躍的に高め、画像診断・自動運転・生成AIなど、私たちの生活に密接に関わる分野で大きな変革をもたらしています。
人工知能(AI)は、突如として登場した新しい技術ではなく、長年にわたる研究と進化の積み重ねの結果として現在の形に至っています。AIの発展の歴史は、大きく「3つのブーム」と「その間に訪れた冬の時代(AI Winter)」によって構成されています。ここでは、AIがどのように発展してきたのかを時代ごとに見ていきましょう。
人工知能という概念が初めて登場したのは1950年代です。この時期は、AIという学問分野の誕生期とも言えます。1956年に米国ダートマス大学で開催された「ダートマス会議」で、“Artificial Intelligence”という言葉が正式に使われ、AI研究が本格的に始まりました。
当時のAI研究は「推論」と「探索」を中心としており、チェスや数学の定理証明といった課題に挑戦していました。初期の代表的なプログラムとしては、
この時期のAIは「コンピュータが人間のように考える」という夢を抱きながらも、計算機の性能やデータ量の制約により、実用化には程遠いものでした。理論上は可能でも、現実的な処理能力が追いつかず、やがて研究は停滞し「第1次AI冬の時代(1970年代)」を迎えます。
1980年代に入ると、「エキスパートシステム(Expert System)」の登場によってAI研究が再び活発化しました。これは、特定分野の専門家の知識を「ルール」としてシステムに組み込み、問題解決を自動化する技術です。医療診断や設備の故障診断など、限られた領域で成果を上げました。
代表的な例としては、
しかし、これらのシステムは「ルールベース」であるため、知識の追加・修正が非常に困難で、膨大なルールを人間がメンテナンスしなければならないという課題がありました。また、知識の曖昧さや例外への対応が難しく、次第に限界が明らかになります。このため1990年代に入ると再びAIへの関心が薄れ、「第2次AI冬の時代」を迎えました。
2000年代後半から2010年代にかけて、AIは再び劇的な進化を遂げます。その原動力となったのが「ディープラーニング」と「ビッグデータ」、そして「高性能GPU」の登場です。
特に2012年、トロント大学のHinton教授らが開発した**ディープニューラルネットワーク(DNN)**が画像認識コンテスト「ImageNet」で圧倒的な精度を達成したことが、AIブーム再来の決定打となりました。これをきっかけに、AIは実験段階から実用化段階へと急速に発展します。
この第3次AIブームの特徴は、理論ではなく「実用性」に重点が置かれている点です。AIはスマートフォン、SNS、クラウドサービス、IoTデバイスなどに組み込まれ、私たちの日常生活に深く浸透しています。
たとえば:
これらの技術の進歩により、AIはもはや「未来の技術」ではなく、「社会インフラの一部」となりました。さらに、近年では生成AIの登場によって、AIは「人間の知的作業を支援する存在」から「創造する存在」へと進化しつつあります。
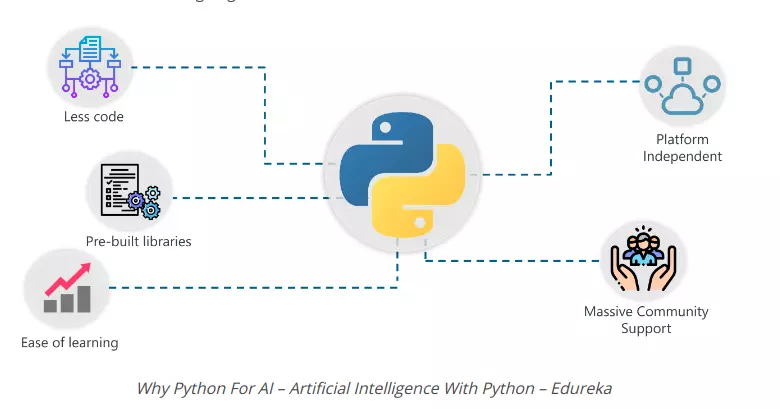
近年のAI開発において、最も広く使用されているプログラミング言語の1つが Python(パイソン) です。Pythonはシンプルで読みやすい文法を持ち、数多くのAI・機械学習用ライブラリが充実していることから、研究から実務まで幅広い分野で利用されています。
この章では、PythonがなぜAI開発において中心的な役割を果たしているのか、その理由を具体的に解説します。
AI分野では、アルゴリズムの実装よりも「データの前処理」「モデルトレーニング」「結果の評価・可視化」など、実験的な作業が多く発生します。Pythonはこれらの作業をスムーズに行えるよう、柔軟で扱いやすい構文と豊富なツール群を備えています。
主な理由は以下の通りです。
これらの特徴により、Pythonは「AIを学ぶための言語」であると同時に、「実際のAIシステムを構築するための言語」として確立されました。
PythonがAIにおいて圧倒的な地位を築いている理由のひとつは、強力なオープンソースライブラリ群の存在です。それぞれのライブラリは異なるフェーズで役割を果たします。
| フェーズ | 代表ライブラリ | 主な用途 |
|---|---|---|
| データ処理 | NumPy / Pandas | データの整形・集計・欠損値処理 |
| 可視化 | Matplotlib / Seaborn | グラフやヒートマップでの分析結果表示 |
| 機械学習 | Scikit-learn | 回帰・分類・クラスタリングなどの基本モデル |
| 深層学習 | TensorFlow / PyTorch / Keras | ニューラルネットワークの構築・学習・推論 |
| 自然言語処理 | NLTK / SpaCy / Transformers | テキスト解析や言語モデルの実装 |
たとえば、企業が「商品レビューの自動分析」を行う場合、
このようにPythonは、AI開発の「一貫したワークフロー」を実現する強力なプラットフォームとなっています。
Python は学びやすく、AI 開発に必要なエコシステムが整った言語です。
企業が AI 活用を推進する中で、Python × ベトナム オフショア開発の組み合わせは、コスト・スピード・品質のバランスが取れた最適解といえます。
開発を成功させる鍵は、「小さく始めて、継続的に改善する」こと。そして、信頼できるパートナーと共に歩むことです。
HEROES/HV TECH は、日本法人の安心サポートとベトナム拠点の実装力を組み合わせた「伴走型開発」で、企業のAI導入を支援しています。




